Doctor Edmond J. Yunis
Profesor de Patología de la
Escuela de Medicina
Universidad de Harvard
Boston, Massachusetts USA
Doctor Iván Yunis
Research Fellow de Pediatría de la
Escuela de Medicina
Universidad de Harvard
Boston, Massachusetts USA
Introducción a la Inmunogenetica
Inmunogenética es el campo de la inmunología y de la genética que estudia los genes que controlan la síntesis de los productos celulares que están involucrados en la respuesta inmune, y en menor grado, de la variabilidad de estas proteínas usando métodos inmunológicos.
Aunque se sabe que existen por lo menos 10 sistemas genéticos que interactúan en la producción de las células y/o factores de la respuesta inmunológica, los dos más importantes y mejor estudiados son: el complejo mayor de histocompatibilidad y los genes de las cadenas pesadas de las inmunoglobulinas. En esta conferencia describiremos, y sólo de manera introductoria, el complejo mayor de histocompatibilidad (CMH), también llamado HLA.
Los productos de los genes del CMH se definen como las glicoproteínas de la membrana celular que son reconocidas por receptores en la membrana de los linfocitos T.
Las células T constituyen la mayor parte de los linfocitos circulantes; son células que reciben su educación en el timo durante el período prenatal y postnatal de tal modo que desarrollan la capacidad de reconocer solamente los antígenos del CMH del propio individuo sin que ello desencadene la activación celular.
Sin embargo, los receptores de las células T pueden provocar la activación cuando un antígeno extraño (viral, bacteriano, químico, etc.) se combina con una molécula del CMH. Así se inicia la respuesta inmunológica (Fig. 1). (Lea también: Química de los Antígenos HLA (CMH))

Los linfocitos T se subdividen en varias clases de acuerdo con sus funciones y con los diferentes marcadores de la membrana celular (proteínas identificadas por anticuerpos). Por ejemplo, las células T ayudantes o auxiliares (A) en el humano se reconocen por un marcador especial CD4 y las células T (C) citotóxicas -que constituyen un número menor de células circulantes- por un marcador especial CD8.
Estas dos clases de células constituyen las células efectoras más importantes en la respuesta inmune (Fig. 2).
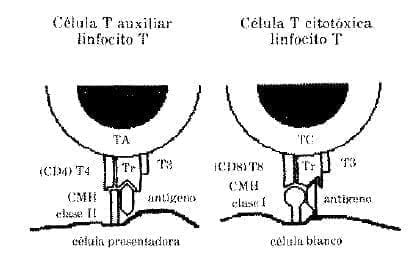
Hipótesis para explicar el reconocimiento del antígeno por células T. La molécula CMH de clase II con un antígeno es reconocida por la molécula CD4 en unión del complejo T3 con el receptor de tal modo que existe restricción. En cambio la célula citotóxica estimulada por una célula blanco reconoce a la molécula CMH clase 1en unión con antígeno por medio de la molécula CD8 unida al complejo T3 con el receptor, produciendo restricción inmunológica.
Modificado de Roitt. I. et al. (1).
Las células T (A) proliferan en presencia de las glicoproteínas del CMH llamadas antígenos de histocompatibilidad de clase II y las células T (C) proliferan en presencia de las glicoproteínas del CMH llamadas antígenos de histocompatibilidad de clase 1.
Claro que la activación y proliferación de estas células no ocurre normalmente en ausencia de un antígeno puesto que cada individuo elimina (en el timo), durante la vida fetal, las células capaces de reaccionar con los antígenos del CMH propios.
Por lo tanto, la activación y proliferación de los linfocitos T ocurre cuando los receptores de las células T (A) reaccionan con moléculas de clase II en conjunto con antígenos extraños como antígenos virales o bacterianos. Y los receptores de las células T (C) reaccionan principalmente con moléculas de clase 1 en conjunto con antígenos virales.
Es importante observar que la reacción de las células T (A) con el complejo molécula de clase IIantígeno, que ocurre por intermedio de células adherentes como el macrófago, es una reacción del brazo aferente de la respuesta inmune.
En cambio, la reacción de las células T (C) con el complejo molécula de clase 1- antígeno, que ocurre con células blanco por ejemplo infectadas por virus, es una reacción del brazo eferente de la respuesta inmune.
Los linfocitos T (A) activados también interactúan con otras células del sistema inmunológico para producir diferentes reacciones: de inmunidad humoral, mediadas por linfocitos B que sintetizan anticuerpos; de inmunidad celular, mediada por linfocitos T (C) que inducen citotoxicidad, o de hipersensibilidad retardada (tipo tuberculina) en la que participan monocitos.
Es necesario hacer hincapié en este momento en que las moléculas más importantes de la inmunidad específica son los antígenos de histocompatibilidad de clase II, que combinados con una sustancia extraña (antígeno) son presentados por la célula adherente (el macrófago) a los linfocitos T auxiliares. Sin esta reacción la mayoría de las respuestas inmunológicas específicas no ocurriría.
Un hecho interesante es la existencia de antígenos pequeños llamados haptenos que requieren moléculas transportadoras para que puedan producir reacciones efectoras de inmunidad humoral o celular. Sin embargo, pueden provocar la activación de una tercera clase de linfocitos T, llamados supresores (Ts) puesto que son capaces de regular la respuesta inmune.
Con base en las interacciones normales de las células que participan en la respuesta inmune ha sido posible determinar que existen genes de respuesta inmune (Ir) –principalmente los del CMH de clase II- y que el vigor o la debilidad de una respuesta inmunológica depende de la presencia o alteración de la interacción entre el antígeno con las moléculas de clase II y el receptor de las células T (A).
Estos fenómenos de interacción incluyen: a) la normalo defectuosa presentación del antígeno, b) la presencia o ausencia de células T que reconozcan el antígeno en conjunto con moléculas clase II y c) la proliferación de células T (A) concomitantemente con la proliferación normal o excesiva de células T supresoras (Fig. 3).
Como se ve en el diagrama, existen interacciones entre las células supresoras (Ts), las células T auxiliares (TA) y los linfocitos B. Es necesario tener en cuenta que la interacción entre células y anticuerpos en la regulación de la respuesta inmune es compleja y el diagrama es muy simplificado.
Se conocen dos formas de inhibición mediadas por anticuerpos: la red de idiotipos-antidiotipos y mecanismos de retroalimentación frente al antígeno. En la primera, la región variable de la inmunoglobulina puede provocar una reacción antígeno-anticuerpo que por sí misma es inhibitoria.
La inhibición puede ser celular -mediada por células supresoras- mientras que en la estimulación las células presentadoras de antígeno lo presentan a las células auxiliares y a los linfocitos B. Al mismo tiempo las células T auxiliares al activarse ayudan a los linfocitos B a producir anticuerpo (Fig. 3). Otro factor importante es la catabolización del antígeño que disminuye su capacidad antigénica.
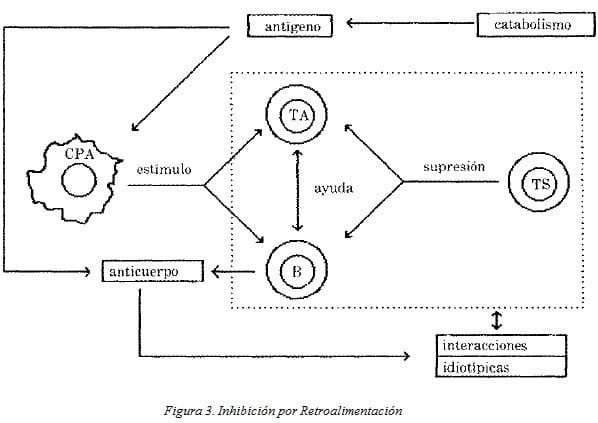
Regulación de la respuesta inmune: un modelo mínimo de controles por anticuerpo, por células y por catabolismo del antígeno.
CPA = célula presentadora de antígeno (célula adherente, i.e. macrófago)
TA = célula auxiliar (linfocito T)
B = linfocito B
TS = célula supresora (linfocito T)
El Código Génetica
La información genética se encuentra en los ácidos nucléicos de las células. Los ácidos nucléicos son moléculas complejas compuestas por nucleótidos cada uno de los cuales está compuesto por una base nitrogenada, un azúcar y un fosfato.
Las sustancias nitrogenadas se llaman purinas y pirimidinas. Las purinas son la adenina y la guanina y las pirimidinas son la citosina, la timina y el uracilo. Existen dos clases de ácidos nucléicos: uno contiene el azúcar ribosa y se llama ácido ribonucléico (ARN), el otro contiene deoxiribosa y se llama ácido deoxiribonucléico (ADN).
El ARN se halla en el nucléolo y en el citoplasma y el ADN en los cromosomas. Ambas clases de ácidos nucléicos contienen citosina e idénticas clases de bases purínicas, pero mientras la timina se localiza en el ADN, el uracilo lo hace en el ARN

Los genes están compuestos por ADN, molécula que debe poseer una estructura variable y capaz de reproducirse. La molécula está formada por dos cadenas de nucleótidos unidas entre sí por puentes de hidrógeno entre las bases nitrogenadas. La conformación espacial es la de una hélice doble.
Las bases se unen ordenadamente por intermedio del hidrógeno: una purina siempre se enlaza con una pirimidina- guanina con citosina y adenina con timina. El ADN se transmite de una generación a otra porque cada cadena se separa y puede duplicarse en una cadena complementaria (Fig. 4).

La molécula de ADN, compuesta de 2 cadenas de nucleótidos, la espalda de cada cadena está formada por las moléculas de azúcar y fosfato. Durante la replicación las 2 cadenas se separan de tal modo que cadenas complementarias se sintetizan.
La información genética se encuentra en el ADN en la forma de tripletes; tres bases codifican un aminoácido, constituyendo el Codón. La información guardada en el código se transmite del ADN a un tipo de ARN (el mensajero). El proceso por el cual la información es transmitida se conoce como transcripción, y la información del ARN se traslada a la síntesis de proteínas mediante un proceso llamado traducción (Fig. 5).

La estructura del gen está compuesta por exones e intrones. La transcripción el gen comienza en la vecindad de lacaja TATA (secuencia rica en adenina y timina). El ADN se transcribe para formar el precursor ARN con exones e intrones. De esta clase de ARN se eliminan las secuencias que corresponden a los intrones quedando el ARN mensajero (ARN-m). Los codones del ARN -m se traducen dando origen a la proteína en los ribosomas.
Modificado de Emery, A. (2).
Sólo un 20% de la información contenida en el ADN humano se transcribe y sirve para sintetizar proteínas; el 80%restante lo constituye ADN repetitivo, además de secuencias no repetitivas, cuyo mensaje no se transcribe.
Las secuencias de un gen que se transcriben se denominan exones; aquellas que a pesar de estar interpuestas entre los exones no codifican aminoácidos en la proteína, se denominan intrones. Durante la división nuclear las dos cadenas de ADN se separan y las bases complementarias forman una nueva cadena.
De este modo cuando las células se dividen, la información genética se conserva y es transmitida sin cambio alguno a las células hijas. La información almacenada en el código del ADN va del gen a un tipo de ARN llamado mensajero.
El ADN es complementario al ARN: citosina con guanina, adenina con uracilo. El ARN mensajero migra del núcleo al citoplasma donde se asocia con ribosomas formando una horma en donde los aminoácidos se alinean en secuencia. Estos aminoácidos son activados por el trifosfato de adenosina (ATP) agregado a cada ARN de transferencia (Fig. 6).
Después, el ribosoma mueve el ARN uniendo a los aminoácidos para formar una cadena polipeptídica. El gen es pues un segmento de ADN que codifica la síntesis de una proteína funcional; este segmento, de longitud variable según el gen, se mide en kilo-bases o unidades de 1000 bases (nucleótidos).

Diagrama que representa el modo como la información genética He traduce en síntesis de proteína.
La Biología Molecular: Genes Recombinantes e Ingeniería Genética
Existen varios aspectos de la biología molecular cuya definición es importante en nuestro resumen: variantes genéticas como las mutaciones, el aislamiento de genes, la técnica de Southern y la ingeniería genética.
Las mutaciones son los cambios del código genético resultantes de sustituciones de bases nucleotídicas del ADN que pueden producir errores en la traducción del gen a su proteína correspondiente. La secuencia de un gen puede cambiar sin que ello altere su funcionamiento o la estructura de la proteína a la cual codifica.
Esto puede producirse por recombinación o por conversiones genéticas de secuencias de nucleótidos transferidas a distancias variables del cromosoma. Otras veces, el cambio en la secuencia del gen puede conducir a un defecto en la función que desencadene una enfermedad.
Los genes pueden aislarse con el uso de sondas genéticas. Estas sondas se obtienen mediante la introducción de un fragmento dado de ADN en un vector que puede reproducirse en bacterias; a este proceso se le denomina clonaje.
El ADN “clonado” puede ser marcado, por ejemplo, con el fosfato radioactivo y ya que típicamente hibridiza con otro ácido nucléico complementario es posible recono. cer el gen o su ausencia (deleción) en un genoma determinado.
Estas sondas pueden ser producidas con base en la secuencia de aminoácidos de su gen putativo el cual puede ser sintetizado con el uso de polimerasas. Toda esta revolución científica se basó principalmente en dos descubrimientos: las endonucleasas de restricción y la producción de vectores en donde se puede incorporar un segmento de ADN (plasmidos, fagos, etc.) y que puedan reproducirse o replicarse en bacterias. Las enzimas de restricción escinden el ADN (Fig. 7) en sitios específicos.
Las porciones del ADN resultante pueden ligarse a cualquier ADN, generando moléculas combinadas en las que una secuencia se añade a otra en el orden deseado, formando así una molécula de ADN “recombinante”.

Un vector que contenga toda la secuencia de nucleótidos de un gen puede ser utilizado en la producción de proteínas por bacterias, proceso denominado ingeniería. Genética. Se espera que esta forma de ingeniería se pueda usar en el futuro para el tratamiento de enfermedades secundarias a defectos genéticos.
El ADN existe en las células dizigóticas en cadena doble que puede disociarse aumentando la temperatura. Las dos cadenas pueden reasociarse si poseen secuencias nucleotídicas complementarias (Fig. 8).

En el caso del uso de enzimas de restricción se sabe que la enzima EcoRI, por ejemplo, reconoce una secuencia específica de cuatro nucleótidos AATC, localizados entre dos guaninas (Fig. 7). Cada vez que la enzima encuentra tal secuencia se fija a ella, y, rompiendo los enlaces entre guanina y adenina de cada cadena complementaria, genera dos fragmentos con extremos cohesivos y complementarios.
Dos cadenas de ADN cortadas con la misma enzima tienen, pues, los mismos extremos, lo que permite entonces ligar por ejemplo, un ADN humano a un ADN viral generando una molécula “recombinante”. En el caso típico, un ADN humano se recombina con el ADN de un plásmido bacteriano. El plásmido recombinante se introduce en una bacteria, quien le servirá de “huésped” para su replicación.
La presencia en el plásmido de un gen de resistencia a un antibiótico le permitirá a la bacteria “huésped” sobrevivir en un medio de cultivo que, conteniendo el antibiótico dado, suprime el crecimiento de cualquier otra bacteria.
Bacteria y plásmido recombinante se replican, y el resultado es una cantidad apreciable de ADN recombinante, que se puede aislar, e incluso separar una vez más del “vector” usando la enzima que permitió unirlos y estudiarlo.
Las sondas se usan también para la identificación de polimorfismos al nivel de genoma. La técnica descubierta por Southern puede estudiar las variaciones de los genes (alelas) de diferentes loci.
Las endonucleasas de restricción permiten fraccionar un gen en intrones o exones de tal modo que los sitios reconocidos por las enzimas pueden estar a diferentes distancias y por lo tanto las cadenas de ADN producen -de individuo en individuo- fragmentos de diferente longitud. }A este fenómeno se le conoce como RFLP (restricción de fragmentos de longitud con polimorfismo) (Fig. 9).
