
Vulnerabilidad urbana
De acuerdo con las Naciones Unidas (2022), la vulnerabilidad se asocia con “las condiciones determinadas por factores o procesos físicos, sociales, económicos y ambientales que aumentan la susceptibilidad de un individuo, una comunidad, activos o sistemas a los impactos de los peligros”.
En el ámbito social, tal como lo muestra el diagrama 3, la vulnerabilidad socioeconómica está mediada por dos tipos de condiciones: las asignadas (raza, edad, salud, sexo, grupo étnico) y las adquiridas (educación, renta, domicilio, entre otras). Dependiendo del contexto (institucional, cultural, etc), las primeras pueden incidir en el acceso a las segundas, lo que define las posibilidades (en favor o en detrimento) de la movilidad social ascendente (Alguacil, 2006). Entonces, la “combinación, por tanto, de múltiples factores de desventaja … llevan directamente a lo que se ha identificado como la exclusión social” (Alguacil, 2006, pp.159)
Diagrama 3. Vulnerabilidad y Precariedad Urbana
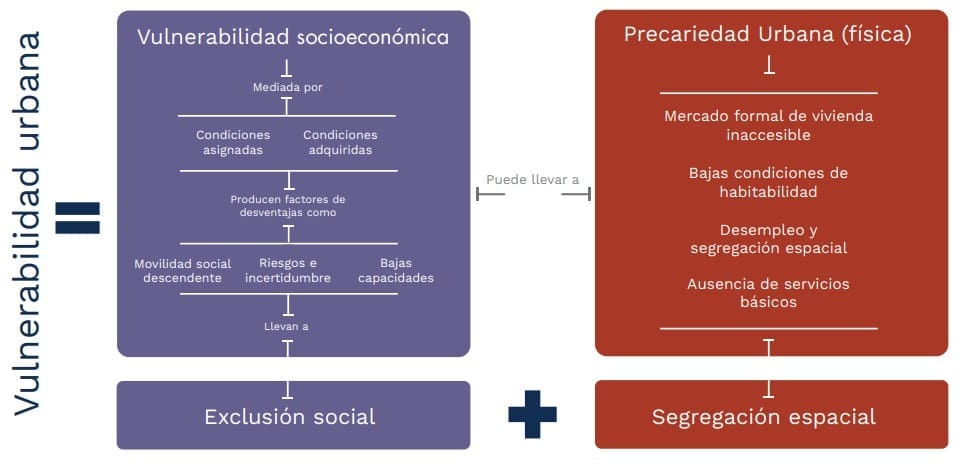
Por tanto, la vulnerabilidad se concentra en el estudio de las condiciones de exclusión que llevan a la población a una situación de desventaja, que los expone a riesgos o incertidumbres, cuyas consecuencias negativas son difíciles de evitar debido a su baja capacidad para enfrentarlos (Ochoa & Guzmán, 2020).
📘 Lea la primera parte –> Indicador de Condiciones de Vulnerabilidad Urbana
La exclusión social impide el acceso de la población al mercado formal de vivienda, obligándolos a ubicarse en zonas de un menor valor inmobiliario, quedando segregadas espacialmente. Las condiciones características de estas zonas son la baja calidad de la vivienda y su entorno (ausencia de servicios básicos de calidad, lejos de oportunidades laborales y bienes y servicios urbanos), lo que se conoce en la literatura como precariedad urbana (Jordán & Martínez, 2009).
Siguiendo a Alguacil (2014), y en el marco de los objetivos de este documento, se define entonces la vulnerabilidad urbana como la suma de condiciones de exclusión social y/o de precariedad urbana. En consecuencia, la medición de vulnerabilidad urbana generada a través del ICVU incorporará variables socioeconómicas de los hogares y de condiciones físicas de las viviendas.
Índice de Vulnerabilidad Social
Luis Triveño; Farid Matuk. Con el apoyo de Adriana Moreno y Mauricio Torres.
La pobreza urbana es frecuentemente medida a través de los ingresos y las Necesidades Básicas Insatisfechas (NBI), la medición más antigua y sencilla en la que un colegiado experto decide: 1) el total de NBI identificadas que es funcional a las necesidades identificadas (salud, educación, empleo, vivienda y servicios); 2) un criterio operativo para definir cada NBI (en educación puede ser sólo primaria o todos los adultos con secundaria); y 3) un umbral de carencias para pertenecer a una categoría dada (con 1 NBI es pobre, con 2 o más NBI es pobre extremo). Esta medición de NBI tiene la ventaja de poder obtenerse a partir de un cuestionario censal.
La alternativa conceptual más reciente es el Índice de Pobreza Multidimensional (IPM), que puede ser vista como una evolución sofisticada de las NBI, en el sentido que expande el número de indicadores utilizados, aplicando ponderaciones basadas en juicios a-priori. Su principal ventaja, como lo es con las NBI, es que requiere de un cuestionario liviano y, por lo tanto, su viabilidad financiera es mayor.
Otra alternativa, es el Índice de Vulnerabilidad Social (IVS), desarrollado por el BM, que implica un cambio de paradigma en la metodología para la construcción de este tipo de indicadores, ya que, tradicionalmente, los indicadores se construyen agrupando por dimensiones y estandarizando las variables, para luego poder ser sumadas o promediadas en una sola medida o número que identifica una unidad de análisis.
En contraste, el IVS utiliza métodos de clasificación no supervisados para agrupar los hogares; dichos grupos al ser ordenados generan una medida de vulnerabilidad para la unidad de análisis, evitando la estandarización y agregación de variables. Adicionalmente, dicha medida de vulnerabilidad se materializa en la espacialización de los datos.
Esta metodología parte de la explotación del cuestionario censal en su integridad. Un primer paso consiste en establecer para cada pregunta censal, qué respuestas indican una necesidad insatisfecha; por ejemplo, nivel educativo alcanzado que puede variar desde analfabeto hasta educación superior completa.
En cuanto a la unidad analítica, todo cuestionario censal tiene un módulo de características colectivas del hogar y otro módulo de características individuales. En ambos casos, las preguntas se presentan como variables dicotómicas, es decir, aquellas que sólo pueden tomar dos valores: presencia (1) o ausencia (0) de un fenómeno o característica. Como la unidad analítica del IVS es el hogar, aquellas preguntas de carácter individual deben ser agregadas, transformándolas en variables continuas a través de un porcentaje.
Si bien una alternativa es dicotomizar las variables continuas, usando una medida de tendencia central como la moda o la mediana, esto reduciría la varianza de la unidad analítica. Por tanto, el IVS mantiene el conjunto de variables dicotómicas y continuas para cada hogar. Para el caso de Colombia, tomando el cuestionario censal del CNPV 2018 (DANE, 2019) el IVS propondría las siguientes variables (Cuadro 1):
Cuadro 1. Variables propuestas por el IVS

Para generar un índice sintético, a cada uno de los hogares urbanos que reporten respuestas a todas las variables seleccionadas se le clasifica en grupos organizados con un criterio de ordinalidad de menor a mayor vulnerabilidad social. La técnica aplicada es la clusterización, la cual consiste en formar grupos a partir de las características de la unidad analítica, en este caso el hogar. Por ejemplo, dividir un grupo de hogares entre aquellos que tienen o no hijos, o que viven en casa o apartamento.
El procedimiento de clasificación por clústeres tiene dos estrategias básicas, uno con enfoque jerarquizado y otro con enfoque no-jerarquizado. Teóricamente, el enfoque jerarquizado es superior pero, debido a los millones de observaciones que tiene un censo, se enfrenta una barrera física de direccionamiento de 32 bits implicando que la máxima matriz cuadrada de datos sea muy grande[4]. Por ello, el IVS adopta el enfoque no-jerarquizado que enfrenta el reto de determinar a-priori el número de clústeres.
Una práctica usual ante la inexistencia de un criterio a-priori para determinar el número de clústeres razonable, es implementar reglas empíricas. Sin embargo, una limitación de esta práctica es que hace uso de criterios subjetivos, los cuales carecen de un proceso de optimización matemática, pero son compensados por el conocimiento y la experiencia de quién los elige[5].
Para el caso del IVS, el criterio subjetivo utilizado es el enfoque de pobreza el cual, usualmente y de manera muy general, clasifica la población de estudio en tres grupos: i) bajo (no pobre); ii) medio (pobre vulnerable); y iii) alto (pobre extremo). En ese sentido, el IVS preserva esta clasificación, sin perjuicio de que pueda ser ajustada, de acuerdo a las realidades nacionales y los objetivos de política.
Por otra parte, el uso de clústeres no-jerarquizados enfrenta el reto de identificar la variable que permita conformar los grupos (punto de arranque), de acuerdo a los requerimientos del algoritmo. De no definirse a-priori el punto de arranque, se encuentra que cada vez los hogares asignados a los tres clústeres son distintos. Esto se resuelve construyendo un indicador auxiliar con base en todas las variables dicotómicas disponibles y luego reagruparlo en grupos que servirán como centroides iniciales.
Finalmente, cuando los datos consisten solamente de variables dicotómicas o solamente de variables continuas, existen varios métodos disponibles en STATA. Ahora, cuando se tiene un caso mixto como el del presente análisis, el único método disponible es el Índice de Disimilaridad de Gower[6] que admite el análisis de variables dicotómicas y continuas, calculando las medianas de los datos en lugar de medias, con el fin de minimizar sesgos por valores extremos. Por tanto, la construcción de grupos de hogares de características comunes con una ordinalidad clara en materia de bienestar, evita establecer umbrales como en las mediciones de pobreza monetaria.
La experiencia previa en la estimación del IVS se evidenció que la segmentación urbano-rural aparece persistentemente al conformar los tres clústeres: uno rural y dos urbanos, lo que sobre-homegeniza las condiciones urbanas, impidiendo focalizar de manera más detallada.
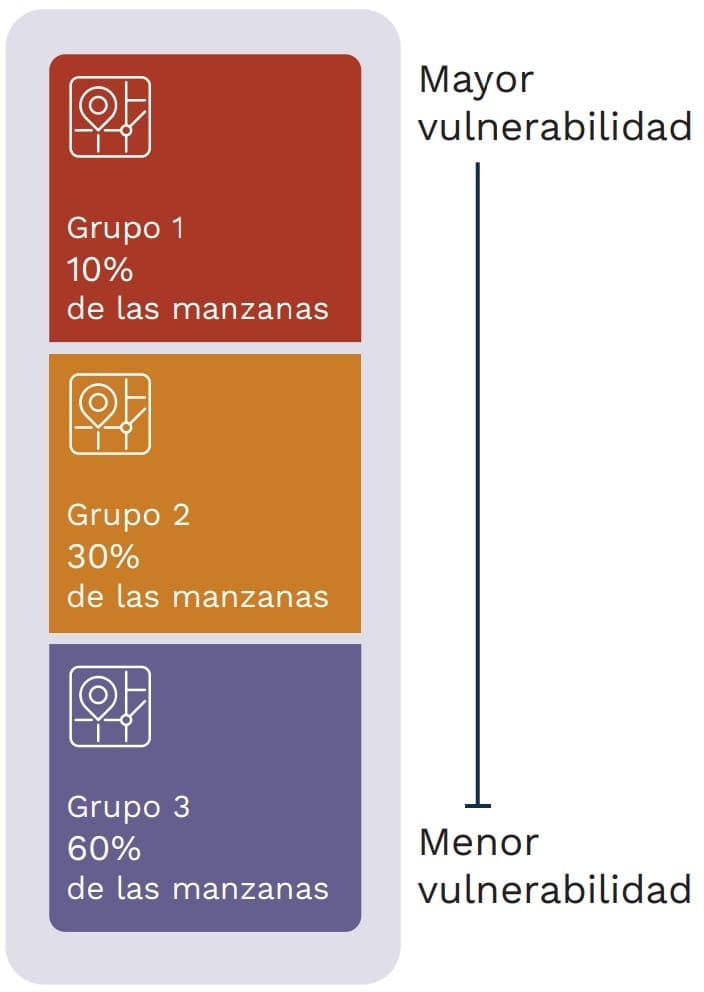
Ahora bien, dado que la información georreferenciada a nivel hogar no es de acceso público, pero sí la de Grupos de vulnerabilidad IVS nivel de manzana, se estima un promedio simple de uno de los 3 posibles valores ordinales que cada hogar nivel de manzana.
Finalmente, para definir el porcentaje de manzanas que van a conformar cada uno de los grupos que se visualizan en los mapas, y siguiendo los criterios usualmente implementados por el BM, el Grupo 1 (G1) correspondería al 10% de las manzanas con mayor vulnerabilidad y el Grupo 2 (G2) agruparía el siguiente 30% de las manzanas (Diagrama 4).
Diagrama 4. Grupos de vulnerabilidad IVS
Como se observa, el IVS propone una metodología simple y de fácil replicabilidad por usuarios de diversas capacidades, que además, permite ser adaptada a las particularidades de los territorios. Adicionalmente, al tomar como fuente datos censales, permite:
- reducir costos de operaciones asociadas al levantamiento de información.
- analizar integralmente de aspectos sociales y físicos, sin juicios a priori.
- visualizar espacialmente los resultados.
- obtener resultados para todo el territorio nacional, facilitando análisis a diferentes escalas territoriales.
- facilitar el uso de los resultados por parte de diversos actores (alcaldías, gobernaciones, áreas metropolitanas, entre otras).
-
[4] En STATA puede ser de 11,000 por 11,000 y en SAS y SPSS es una matriz de 2 Gb.
-
[5] Con el enfoque no-jerarquizado se corre el riesgo de sobre-homogenizar al seleccionar a-priori un número bajo de clúster. El riesgo de sobre-heterogenizar se puede resolver con un ANOVA (analysis of variance) de las variables para identificar si dos clúster son realmente distintos entre sí o no. Para el presente caso, únicamente se hizo una verificación que las diferencias entre grupos fueran reales y que describieran la realidad.
- [6] El algoritmo del Índice de Disimilaridad de Gower es consistente con el implementado en el paquete estadístico STATA.
-
Foto: Residente de un barrio popular Medellín, Colombia. Creditos: BID




